주피터 노트북에서 파이썬 멀티프로세싱 구현하기
우선, 만약 주피터 노트북에서 멀티프로세싱이 구현되지 않아 많은 스트레스를 받은 상태라면 차근차근 읽지 마시고 맨 아래로 내려가 문제 해결방안을 먼저 보셨으면 좋겠다. 앞부분은 주절주절 떠드는 내용이다.
앞선 포스팅들에서 얻은 리뷰 데이터로 텍스트 마이닝을 진행했다.
Konlpy, mecab, Soyspacing, tensorflow, gensim 등등 많은 라이브러리를 사용했는데
이때 Konlpy의 Okt().normalize 를 사용하며 큰 답답함을 느꼈다.
Okt의 처리 속도가 다른 라이브러리에 비해 느리다는 것은 다른 분들의 리뷰를 통해 익히 들어 왔지만 mecab을 주로 사용하여 전처리를 하던 나에게 Okt는 엄청난 느림보였다.
이를 개선하기 위해 코어 하나만 갈구는 파이썬에게 여러 코어를 갈구라고 시킬 수 있는 멀티프로세싱을 구현하기로 했다.
구글링을 하니 쉽다는 말이 많았다
파이썬 멀티프로세싱을 구글링 했더니 매우 많은 내용이 있었고 그 중 좋은사람님의 게시물을 참고했는데 실제로 추가해야 하는 코드도 짧고 굉장히 간단해보였다.
심지어 소스코드까지 제공해주셔서 ‘별거 아니네?’ 라는 생각이 들었었고 재빠르게 소스 코드를 받아 적용했다.
하지만…
그럼 그렇지. 파이썬은 나를 쉽게 보내 줄 생각이 없었다.
Can’t get attribute
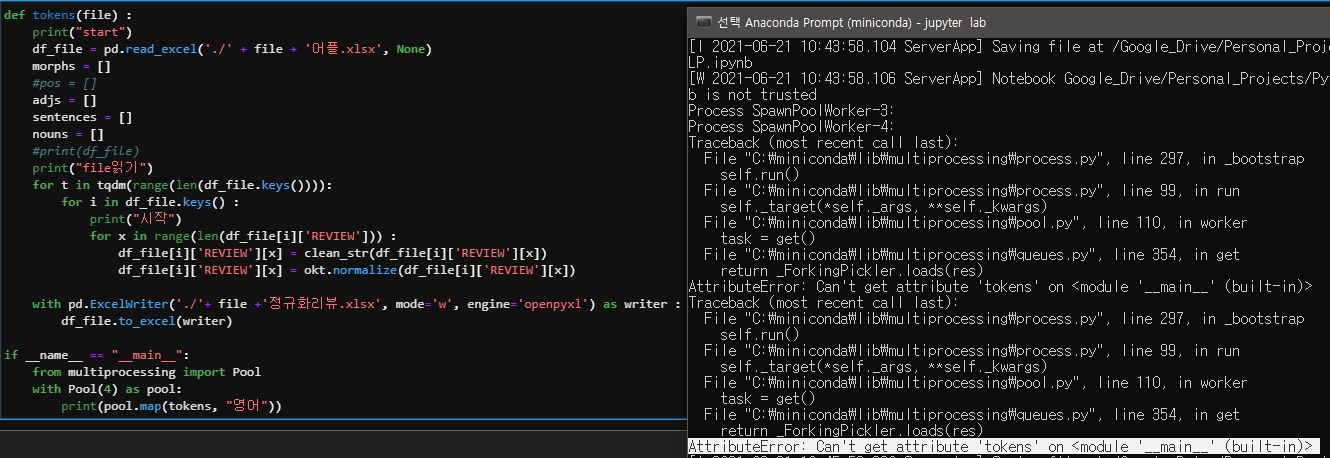
왜째서….tokens는 분명히 작동을 확인한 함수인데 ㅠㅠ
이미 작동이 확인된 함수가 작동을 하지 않았다.
뭐가 문제인지 모르니…3일 동안 스택오버플로우에도 검색해보고 구글링도 해보고 위키 독스도 찾아봤지만 도대체 뭐가 문제인지 자꾸만 attribute를 가져올 수 없다는 내용이 터미널에 등장했다.
그래서 실례를 무릅쓰고 Tensorflow KR 페이스북 그룹에 질문을 올렸다. 당시에 텐서플로 관련 질문이 아님에도 친절히 답변해 주신 모든 Tensorflow KR 페이스북 그룹 사용자 여러분께 다시 한번 감사를 표한다.
우선, 먼저 지적해주신건 최하단의 pool.map() 부분이었다.
pool.map()에는 iterable이 들어가야하는데 나는 tokens, “영어”를 입력했고 이 부분을 tokens, [“영어”] 로 바꿔야 한다 해주셨다.
하지만…여전했다
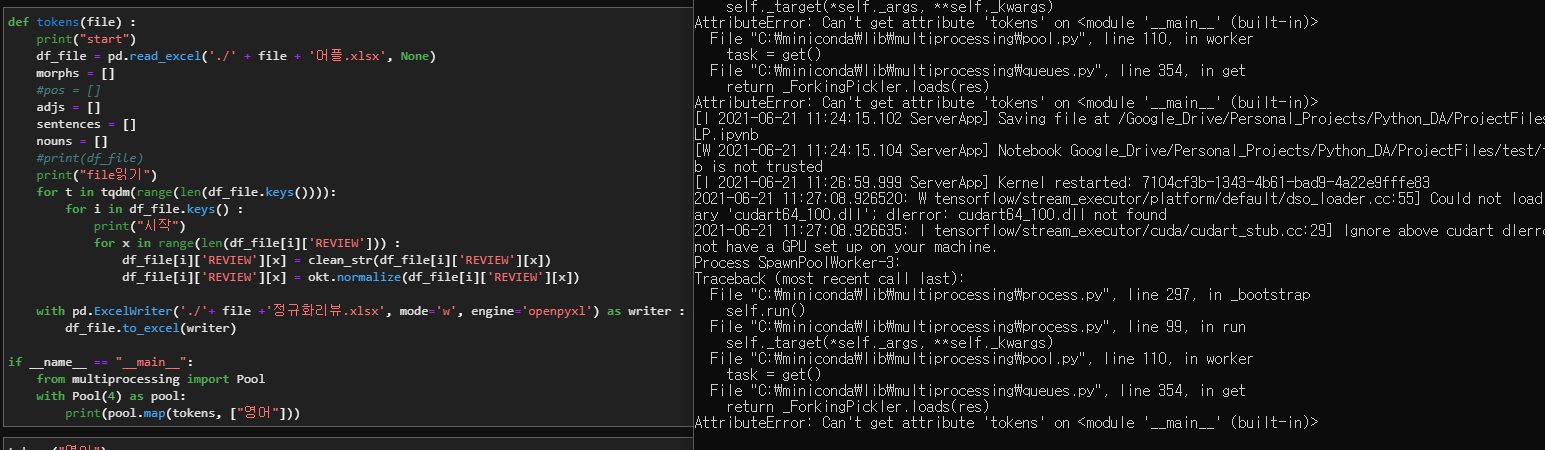
다음으로는 multiprocessing 대신에 joblib.parallel을 사용해보라는 말씀이 있으셨다.
다만…joblib.parallel을 찾아보니 훨씬 낫다는 평이 있긴 했으나 당시에 해당 문제로 소모된 정신력이 어마무시하게 커서 손을 대볼 생각 조차 하지 못했다.
그렇게 시간이 지나고 결국 댓글을 달아주시던 한 분께서 공개 가능한 데이터라면 코드와 샘플을 보내줄 수 있냐고 물어보셨고 나는 감사를 표하며 전달드렸다.
그렇게 잠시후…
이게 문제라고????
파일을 전달받은 분께서 주피터 노트북과 multiprocessing 사이에 문제가 있는 것 같다는 말씀을 해주셨다.
평소에도 주피터노트북 상에서 잘 작동되지 않는 부분이 있어 여러 수정을 거쳤지만 이 문제의 원인이 주피터노트북이라고는 상상도 하지 못했는데…
그렇게 말씀해주신 부분을 참고하여 따로 .py 파일로 해당 코드를 분리하였고 다시 주피터노트북에서 import 하여 실행하니 작동이 됐다.
기쁨과 함께 밀려온 허탈함
당시에 너무나 기뻐 실행 성공한 사진을 찍지 못해 기록은 없지만 옆집에 죄송하게도 소리를 좀 질렀던 기억이 난다.
그렇게 작동한 멀티프로세싱은 한 앱의 리뷰를 처리하는데 7시간 걸린다던 예상시간을 10분으로 줄여버렸고 3일과 반나절 동안의 삽질을 멈춰주었다.
당시 도움을 주신 분의 성함을 공개하고 다시 감사를 표하고 싶지만 아무래도 본인께 허락을 받아야 하는 사안 같아 이름을 밝히지 않고 감사를 표한다.
그리고 그 분께는 며칠 뒤 다른 이유로 또 다시 도움을 받았다.
주피터 노트북으로 입문해 주피터 노트북으로만 파이썬을 사용해본 나라는 입문자에게 그날의 도움은 정말 감사했고 큰 도움이 됐다.
다시 한번 감사드립니다.
혹시나 주피터 노트북에서 멀티프로세싱 구현이 안된다면 위 내용처럼 .py 파일로 따로 작성한 뒤 주피터 노트북에서 import 하는 방식으로 사용해 보시라.
{kind=link}